Building My Own Productivity Voice Agent
Why voice wins
Science fiction has been telling us this for sixty years - from Star Trek's computer to Her - but the deeper reason voice will dominate isn't cultural, it's physical. Voice is the only modality that doesn't ask you to stop what you're doing.
I can talk to an assistant while I'm driving. While I'm walking the dog. During a workout. None of those moments are compatible with pulling out a phone, let alone opening a laptop - but all of them are moments where ideas show up. In fact, those "hands busy, mind free" moments are when my best ideas tend to arrive. A voice agent turns them from lost thoughts into captured ones, and sometimes into already-executed ones.
Voice isn't right for every context - open offices, crowded trains, and quiet evenings on the sofa with someone else still belong to typing. And there's a separate, important conversation to have about when we should reach for an AI at all: if I'm out walking the dog, I'd usually rather hear the birds than dictate a Jira ticket. But the point isn't that voice should replace everything. The point is that voice unlocks new situations where productive interaction with software simply wasn't possible before.
That's why the model underneath matters so much. Today's mainstream voice assistants are too hobbled to take advantage of any of this - they can't reach the tools I actually use, and they aren't smart enough to do real work. Native voice models like GPT Realtime 2 are the first ones that feel like talking to a capable colleague rather than dictating to a search box.
The model that finally makes it work
OpenAI's new GPT Realtime 2 model, only available via API at the time of writing, has shown what this could look like: a realtime voice model for speech-to-speech interactions with configurable reasoning effort, stronger instruction following, and more reliable tool use for complex voice-agent workflows.
That last part is crucial. It's no longer a transcription pipeline duct-taped to a chat model and a TTS engine. It's a single model that hears you, reasons, calls tools across your productivity stack, and talks back. The latency drops, the conversation feels natural, and suddenly your assistant is something you actually want to use to get work done.
What I learned building Jarvis
To see how far this could go, I built my own application called Jarvis - a voice agent with access to Todoist and Notion via MCP.
Here is a video showing it in action:
Jarvis can:
- Find my tasks, create new ones, and change their priority or project in Todoist.
- Create and update pages in Notion, and move them between databases.
- Do all of this inside a natural, free-flowing conversation.
Here is how it works:
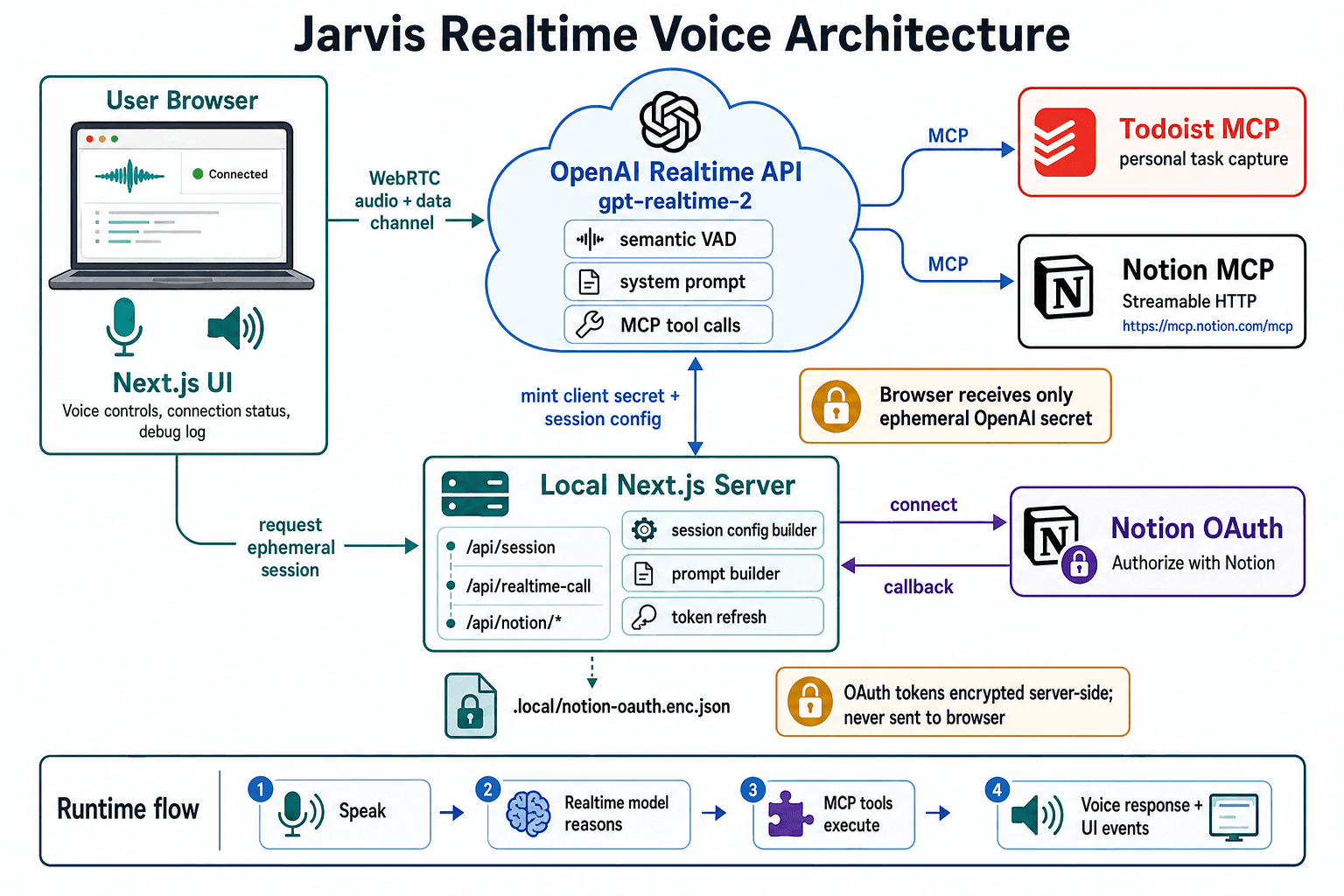
It genuinely feels like the next step in productivity, because the interaction is effortless. No tapping through menus, no context switching - just thinking out loud and watching the system keep up.
Prototype vs. product
Building Jarvis was also a sharp reminder of how much harder productizing this is than prototyping it.
Wiring up tools for myself was simple. Doing the same thing as a SaaS product is a different problem entirely: every user needs their own authenticated connections to their own tools, managed securely and reliably.
On top of that, real-world robustness is its own challenge:
- Picking the right tool, with the right arguments, every time.
- Handling bad microphone quality.
- Surviving network interruptions and changing connectivity.
Getting to a prototype that lets you feel the power of a native voice model is exciting and relatively fast. Turning that into something I'd rely on every day for my productivity is a much bigger lift.
Why OpenAI should embed this into ChatGPT
This is exactly why I hope OpenAI embeds its realtime voice model directly into the ChatGPT app - and in doing so, turns ChatGPT into the productivity agent everyone uses every day.
They've already solved the hardest non-model part of this:
- Server-side integrations. ChatGPT authenticates your productivity tools once and keeps the connection alive on the server.
- Cross-device, cross-modality. Those connections are available everywhere you use ChatGPT - the ChatGPT app, Codex on the Mac, and so on.
If they extend that same integration layer to the realtime voice model, every productivity tool you've already connected becomes instantly usable by voice. That's the unlock: a single, always-available productivity agent you can just talk to, anywhere, that already knows your tasks, notes, and calendar.
The one missing piece I'd add: a watchOS app, so I could capture a task or check my day on the go without my phone.
The next frontier is the living room
There's a second wave coming, and it's already in tens of millions of homes: the smart speaker.
Alexa, Google Home, and HomePod have been sitting on kitchen counters and nightstands for almost a decade, bottlenecked not by hardware or distribution but by the intelligence of the model behind them. They've been good at timers and music and bad at basically everything else. That ceiling is about to lift.
Alexa+ is the first serious attempt by a big tech company to drop a genuinely capable AI into the living room - not as a chatbot you summon, but as an agent that lives in the room with you. Once that pattern works (still work in progress based on my own experience with Alexa+ on an Echo Show 8), the implications are huge. Imagine being on the sofa and just saying "schedule a 1:1 with Sarah next week and pull together the open threads from our last three meetings," or "spin up a small Python script that renames these photos by date" - and having it happen without you lifting a finger or unlocking a screen.
That's a different product than ChatGPT-on-your-phone. It's ambient, shared, always-on, and tied to a specific physical space. It's also the most natural endpoint for everything I described above: voice is the interface, the room is the device, and the model is finally good enough to make it worth using for real work - not just lights and music.
Who else could land this?
OpenAI and Amazon aren't the only companies that could land this. There are a handful of others with realistic - and very different - routes to the same outcome.
Google / DeepMind are the most obvious. They have a top-tier voice model in Gemini, the device footprint to match it (Android, Pixel, Google Home), and tight integration with Gmail, Calendar, Docs, and Drive. And crucially, that stack isn't just a work stack - millions of people also live their private lives in Gmail, Google Calendar, Docs, and Photos. If Google shipped a realtime voice agent across Assistant and Home, with Workspace as the tool layer, they'd be running OpenAI's playbook with a deeper grip on the productivity tools people use both at work and at home.
Notion is the wildcard, and the most interesting one to me. They don't need to invent a voice model - they're model-agnostic and could simply plug in GPT Realtime 2, or whatever wins next. What they do have is the part everyone else struggles with: a single, AI-native surface that already contains tasks, docs, projects, databases, and meeting notes for the people who use it. For a Notion user, "voice agent over my workspace" isn't a stretch - it's the obvious next product. A great voice layer on top of Notion AI would be a complete productivity agent for an enormous slice of knowledge workers, without Notion ever having to own the model or the hardware.
Apple is the sleeping giant. Nobody can match their device footprint - iPhone, Watch, AirPods, HomePod, Vision Pro - and they already have a voice brand in Siri, however dated it currently feels. Their preference for on-device models has kept Siri behind, but the moment they ship a credible realtime voice model (their own, or licensed) plumbed into Shortcuts, Calendar, Reminders, Mail, and the third-party app ecosystem, they overnight have the most ambient productivity agent on the market. There are also persistent rumors of a new device that fuses a HomePod and an iPad into a single countertop product - a smart speaker with a screen, designed to sit in the kitchen or on a desk. If that ships alongside a real Siri upgrade, Apple suddenly has a purpose-built endpoint for exactly the living-room scenario above, on top of all the hardware they're already in.
Sonos is the dark horse. They don't have a voice model, an OS, or a productivity stack of their own - but they have something the others don't: speakers that are actually distributed through the home, room by room. They already partner with Amazon to bring Alexa onto their speakers, so the integration pattern is proven; opening that up to more partners - OpenAI, Google, or whoever wins next - would let Sonos become the ambient layer of the living-room scenario above without ever having to build the brain themselves. It's a partnership play, not a platform play, but in a world where the model is the commodity and the room is the device, "best speakers plus the best model" is a real position.
The bottom line
Voice-native, tool-using AI isn't a gimmick. It's the most natural interface productivity software has ever had, and it's about to become a real product category of its own.
The winners won't just be whoever has the best voice model. They'll be whoever combines a great voice model with deep integrations into the productivity tools people actually use, broad device coverage, and the distribution to put it in everyone's pocket, on their wrist, and in their living room.